publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
- Humanoids2025CoRe: A Hybrid Approach of Contact-aware Optimization and Learning for Humanoid Robot MotionsTaemoon Jeong, Yoonbyung Chai, Choi Sol, Bak Jaewan, Chanwoo Kim, Jihwan Yoon, Yisoo Lee, Kyungjae Lee, Joohyung Kim, and Sungjoon Choi2025 IEEE-RAS 24th International Conference on Humanoid Robots (Humanoids), 2025
Recent advances in text-to-motion generation enable realistic human-like motions directly from natural language. However, translating these motions into physically executable motions for humanoid robots remains challenging due to significant embodiment differences and physical constraints. Existing methods primarily rely on reinforcement learning (RL) without addressing initial kinematic infeasibility. This often leads to unstable robot behaviors. To overcome this limitation, we introduce Contact-aware motion Refinement (CoRe), a fully automated pipeline consisting of human motion generation from text, robot-specific retargeting, optimization-based motion refinement, and a subsequent RL phase enhanced by contact-aware rewards. This integrated approach mitigates common motion artifacts such as foot sliding, unnatural floating, and excessive joint accelerations prior to RL training, thereby improving overall motion stability and physical plausibility. We validate our pipeline across diverse humanoid platforms without task-specific tuning or dynamic-level optimization. Results demonstrate effective sim-to-real transferability in various scenarios, from simple upper-body gestures to complex whole-body locomotion tasks.
- ICRA2025
 Learning-based Dynamic Robot-to-Human HandoverHyeonseong Kim, Chanwoo Kim, Matthew Pan, Kyungjae Lee, and Sungjoon ChoiIEEE International Conference on Robotics and Automation (ICRA), 2025
Learning-based Dynamic Robot-to-Human HandoverHyeonseong Kim, Chanwoo Kim, Matthew Pan, Kyungjae Lee, and Sungjoon ChoiIEEE International Conference on Robotics and Automation (ICRA), 2025This paper presents a novel learning-based approach to dynamic robot-to-human handover, addressing the challenges of delivering objects to a moving receiver. We hypothesize that dynamic handover, where the robot adjusts to the receiver’s movements, results in more efficient and comfortable interaction compared to static handover, where the receiver is assumed to be stationary. To validate this, we developed a nonparametric method for generating continuous handover motion, conditioned on the receiver’s movements, and trained the model using a dataset of 1,000 human-to-human handover demonstrations. We integrated preference learning for improved handover effectiveness and applied impedance control to ensure user safety and adaptiveness. The approach was evaluated in both simulation and real-world settings, with user studies demonstrating that dynamic handover significantly reduces handover time and improves user comfort compared to static methods. Videos and demonstrations of our approach are available at https://zerotohero7886.github.io/dyn-r2h-handover/
2023
- NeurIPS2023
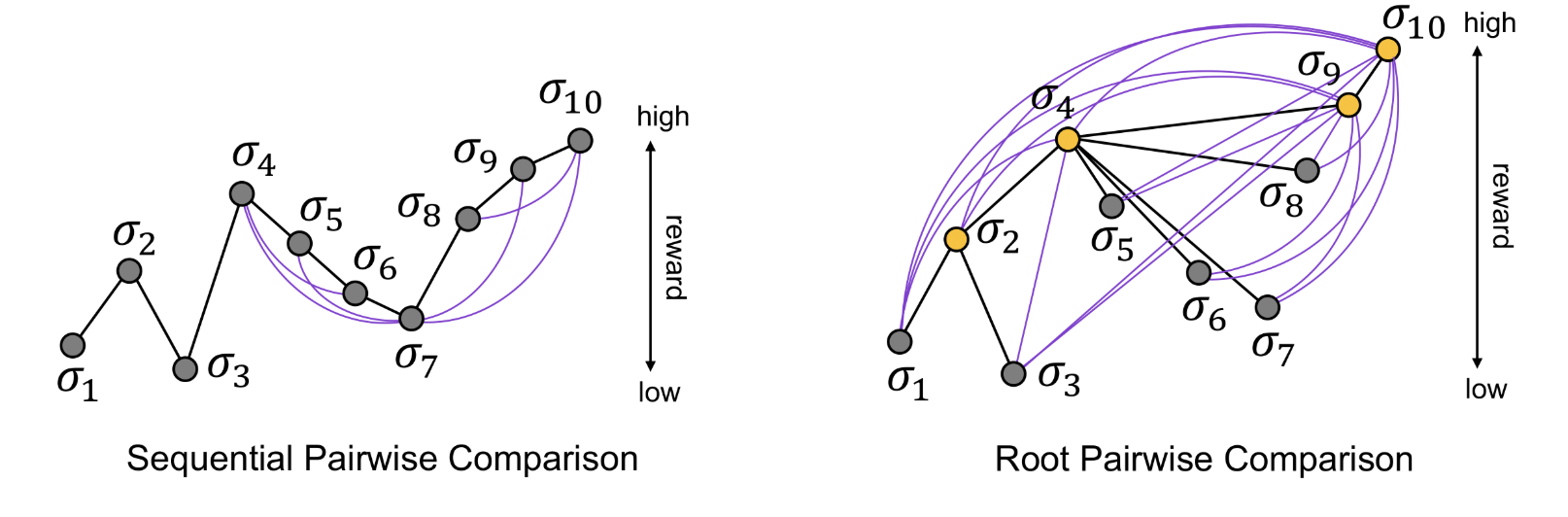 Sequential preference ranking for efficient reinforcement learning from human feedbackMinyoung Hwang, Gunmin Lee, Hogun Kee, Chanwoo Kim, Kyungjae Lee, and Songhwai OhAdvances in Neural Information Processing Systems (NeurIPS), 2023
Sequential preference ranking for efficient reinforcement learning from human feedbackMinyoung Hwang, Gunmin Lee, Hogun Kee, Chanwoo Kim, Kyungjae Lee, and Songhwai OhAdvances in Neural Information Processing Systems (NeurIPS), 2023Reinforcement learning from human feedback (RLHF) alleviates the problem of designing a task-specific reward function in reinforcement learning by learning it from human preference. However, existing RLHF models are considered inefficient as they produce only a single preference data from each human feedback. To tackle this problem, we propose a novel RLHF framework called SeqRank, that uses sequential preference ranking to enhance the feedback efficiency. Our method samples trajectories in a sequential manner by iteratively selecting a defender from the set of previously chosen trajectories K and a challenger from the set of unchosen trajectories U K, where U is the replay buffer. We propose two trajectory comparison methods with different defender sampling strategies: (1) sequential pairwise comparison that selects the most recent trajectory and (2) root pairwise comparison that selects the most preferred trajectory from K. We construct a data structure and rank trajectories by preference to augment additional queries. The proposed method results in at least 39.2% higher average feedback efficiency than the baseline and also achieves a balance between feedback efficiency and data dependency. We examine the convergence of the empirical risk and the generalization bound of the reward model with Rademacher complexity. While both trajectory comparison methods outperform conventional pairwise comparison, root pairwise comparison improves the average reward in locomotion tasks and the average success rate in manipulation tasks by 29.0% and 25.0%, respectively. Project page: https://rllab-snu.github.io/projects/SeqRank